Last time we revisited Robin’s theorem saying that 5040 being the largest counterexample to the bound
\[
\frac{\sigma(n)}{n~log(log(n))} < e^{\gamma} = 1.78107... \]
is equivalent to the Riemann hypothesis.
\[
\Psi(n) = n \prod_{p | n}(1 + \frac{1}{p}) \]
where $p$ runs over the prime divisors of $n$. It is series A001615 in the online encyclopedia of integer sequences and it starts off with
1, 3, 4, 6, 6, 12, 8, 12, 12, 18, 12, 24, 14, 24, 24, 24, 18, 36, 20, 36, 32, 36, 24, 48, 30, 42, 36, 48, 30, 72, 32, 48, 48, 54, 48, …
and here’s a plot of its first 1000 values
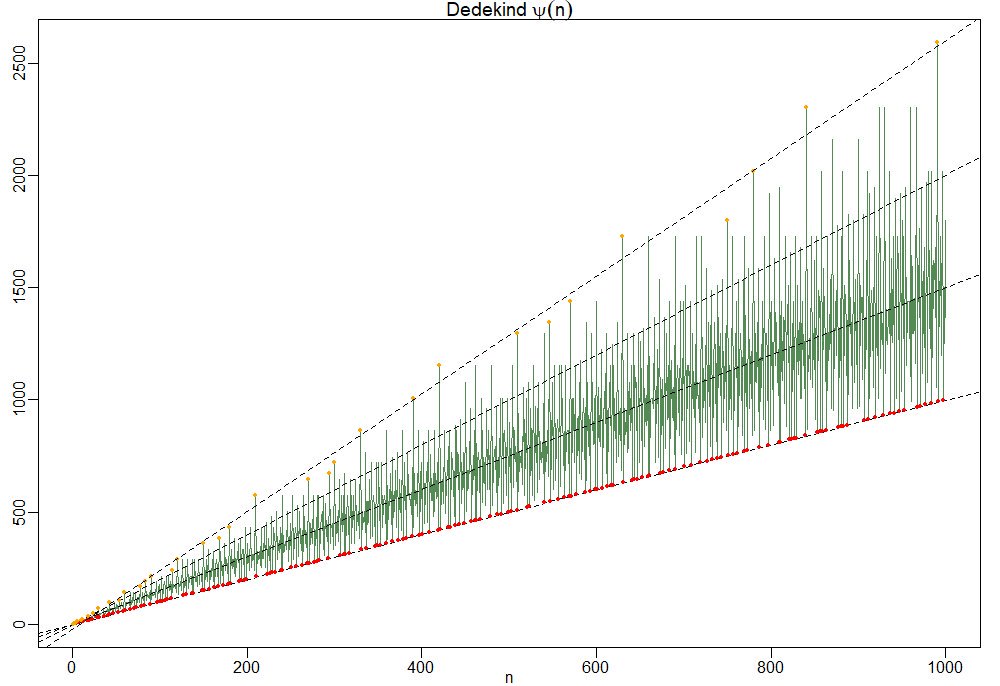
To understand this behaviour it is best to focus on the ‘slopes’ $\frac{\Psi(n)}{n}=\prod_{p|n}(1+\frac{1}{p})$.
So, the red dots of minimal ‘slope’ $\approx 1$ correspond to the prime numbers, and the ‘outliers’ have a maximal number of distinct small prime divisors. Look at $210 = 2 \times 3 \times 5 \times 7$ and its multiples $420,630$ and $840$ in the picture. For this reason the primorial numbers, which are the products of the fist $k$ prime numbers, play a special role. This is series A002110 starting off with1, 2, 6, 30, 210, 2310, 30030, 510510, 9699690, 223092870,…
In Patrick Solé and Michel Planat Extreme values of the Dedekind $\Psi$ function, it is shown that the primorials play a similar role for Dedekind’s Psi as the superabundant numbers play for the sum-of-divisors function $\sigma(n)$.
That is, if $N_k$ is the $k$-th primorial, then for all $n < N_k$ we have that the 'slope' at $n$ is strictly below that of $N_k$ \[ \frac{\Psi(n)}{n} < \frac{\Psi(N_k)}{N_k} \] which follows immediately from the fact that any $n < N_k$ can have at most $k-1$ distinct prime factors and $p \mapsto 1 + \frac{1}{p}$ is a strictly decreasing function. Another easy, but nice, observation is that for all $n$ we have the inequalities\[
n^2 > \phi(n) \times \psi(n) > \frac{n^2}{\zeta(2)} \]
where $\phi(n)$ is Euler’s totient function
\[
\phi(n) = n \prod_{p | n}(1 – \frac{1}{p}) \]
This follows as once from the definitions of $\phi(n)$ and $\Psi(n)$
\[
\phi(n) \times \Psi(n) = n^2 \prod_{p|n}(1 – \frac{1}{p^2}) < n^2 \prod_{p~\text{prime}} (1 - \frac{1}{p^2}) = \frac{n^2}{\zeta(2)} \] But now it starts getting interesting. In the proof of his theorem, Guy Robin used a result of his Ph.D. advisor Jean-Louis Nicolas

known as Nicolas’ criterion for the Riemann hypothesis: RH is true if and only if for all $k$ we have the inequality for the $k$-th primorial number $N_k$
\[
\frac{N_k}{\phi(N_k)~log(log(N_k))} > e^{\gamma} \]
From the above lower bound on $\phi(n) \times \Psi(n)$ we have for $n=N_k$ that
\[
\frac{\Psi(N_k)}{N_k} > \frac{N_k}{\phi(N_k) \zeta(2)} \]
and combining this with Nicolas’ criterion we get
\[
\frac{\Psi(N_k)}{N_k~log(log(N_k))} > \frac{N_k}{\phi(N_k)~log(log(N_k)) \zeta(2)} > \frac{e^{\gamma}}{\zeta(2)} \approx 1.08… \]
In fact, Patrick Solé and Michel Planat prove in their paper Extreme values of the Dedekind $\Psi$ function that RH is equivalent to the lower bound
\[
\frac{\Psi(N_k)}{N_k~log(log(N_k))} > \frac{e^{\gamma}}{\zeta(2)} \]
holding for all $k \geq 3$.
In other words, it gives us the number of tiles needed in the Dedekind tessellation to describe the fundamental domain of the action of $\Gamma_0(n)$ on the upper half-plane by Moebius transformations.

When $n=6$ we have $\Psi(6)=12$ and we can view its fundamental domain via these Sage commands:
G=Gamma0(6)
FareySymbol(G).fundamental_domain()
giving us the 24 back or white tiles (note that these tiles are each fundamental domains of the extended modular group, so we have twice as many of them as for subgroups of the modular group)
.jpg)
But, there are plenty of other, seemingly unrelated, topics where $\Psi(n)$ appears. To name just a few:
- The number of points on the projective line $\mathbb{P}^1(\mathbb{Z}/n\mathbb{Z})$.
- The number of lattices at hyperdistance $n$ in Conway’s big picture.
- The number of admissible maximal commuting sets of operators in the Pauli group for the $n$ qudit.
and there are explicit natural one-to-one correspondences between all these manifestations of $\Psi(n)$, tbc.
Leave a Comment


